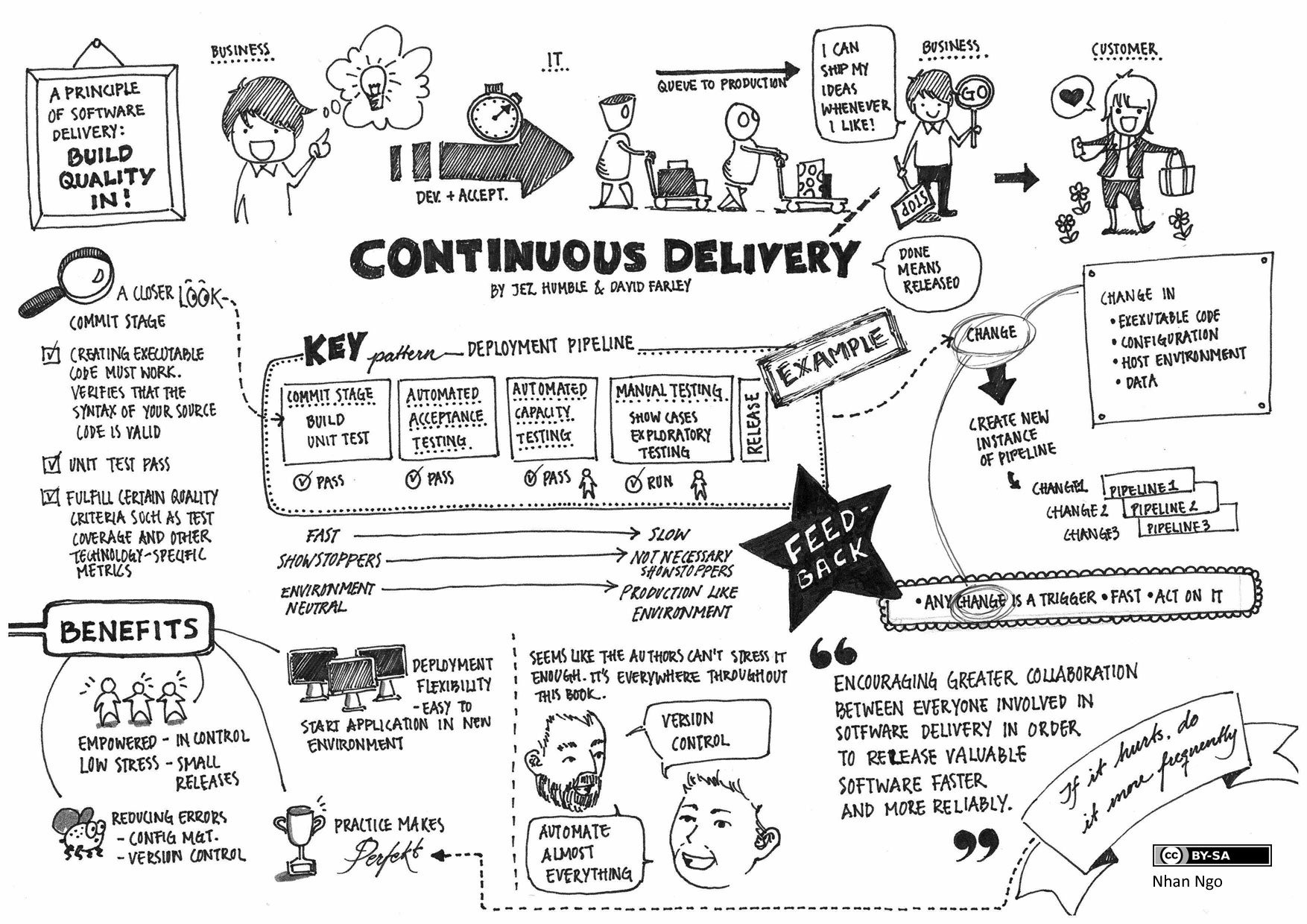
Inching Towards Continuous Deployment

Does this sound interesting?
We're HiringAt Sharethrough, the ability to deploy tested code quickly is critical to our success. When our team was small and local, engineers could verbally announce across the room: “deploying.” But having grown to multiple teams, with offices across timezones, that type of communication breaks down.
After a while, we realized that more communication around deploys was slowing us down. Context needed to be shared to the point that broadcasting could take longer than making the change itself. Since we already used Jenkins for continuous integration, we talked about the possibility of moving into continuous deployment.
Continuous deployment has been a buzzword for some time. There’s even a gif that describes CD in layman’s terms. In short, is the concept of CD is: tested code is immediately deployed into production. Or: ship code faster without losing quality. But how?
{kind=link}
How we used to do it
- Developer writes code, checks into master
- Jenkins runs tests, builds application, deploys to staging
- Some time later, engineer
- Communicates the changes aboout to be deployed
- Deploys to production (via Capistrano)
What we needed was automation to handle everything except Developer writes code, checks into master. Which seemed like a lot. But then Jenkins already handles run tests, builds application, deploys to staging. So all we needed to do was:
- Automate communicates the changes aboout to be deployed
- Deploy so often that automation isn’t too big of a step
- Automate production deploys
Automate communicate changes
Before each production deploy, developers would post outgoing commits to a Slack channel. This served two purposes: notified other developers, “deploying changes” and a saved record in Slack for future reference. The Slack post listed commits messages between the last deploy and the currently-deploying head.
We automated this into Capistrano, building an internal API that used capistrano-slack to Slack outgoing commits to the team whenever an engineer called cap deploy. Which is awesome.

Deploy often
Now that communication was automatic, how could we deploy more frequently?
We noticed that developers had a habit of waiting to deploy until a feature was “done” – seems natural, right? But with multiple features shipping in parallel, a deploy could easily contain over 50 commits, many of which could be unrelated to the deploying engineer’s work. And the “bigger” the deploy, the more risky the deploy. So there was an internal incentive to… wait. Wait until you had communicated to everyone what was being deployed; wait until you’re team-mate finished her work on her feature.
We realized that folks needed visibility into the size (and age) of each change they deployed. We built a dashboard that displayed the number of commits waiting and correlated them to the age of the oldest commit.
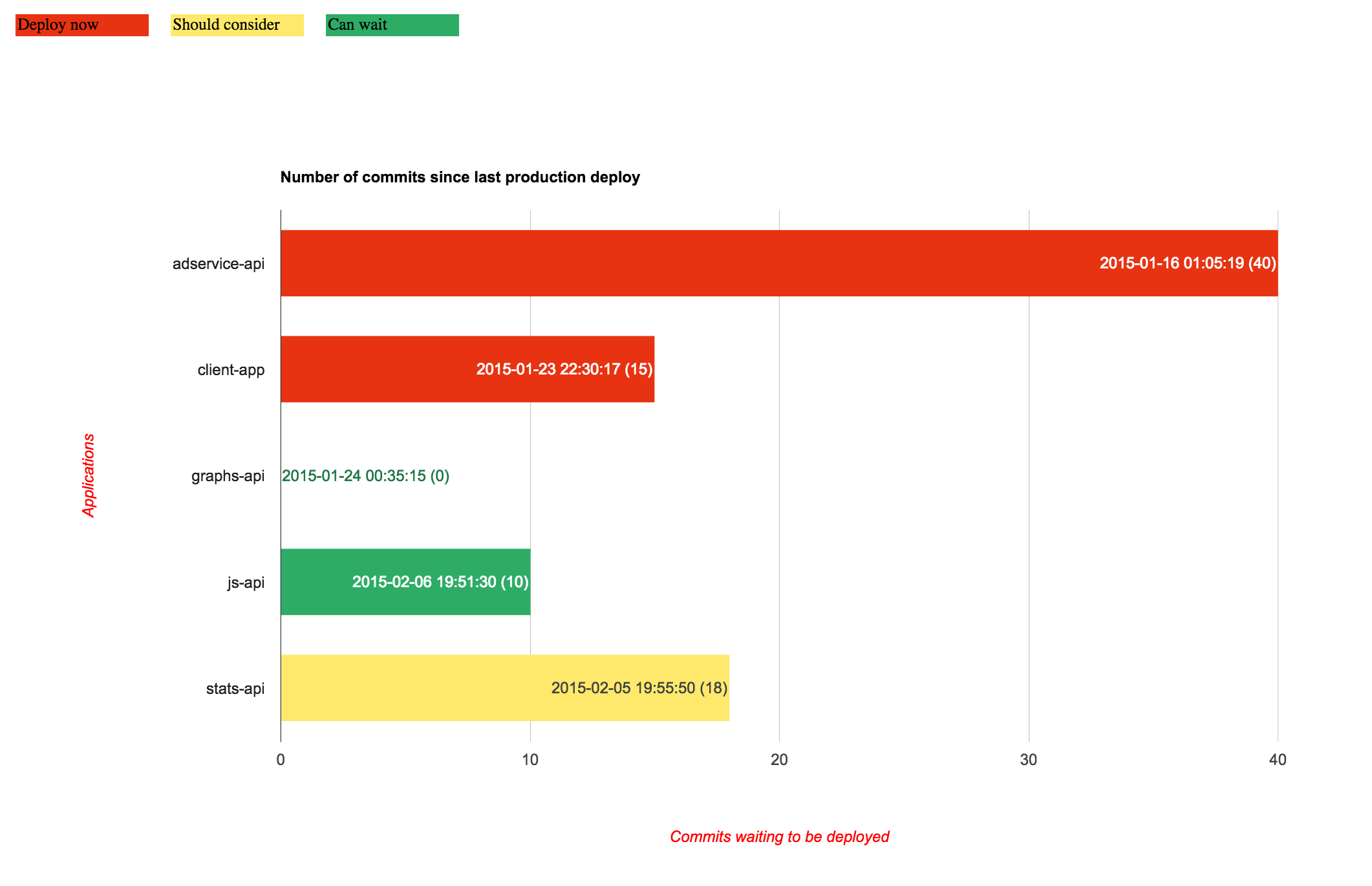
Displaying this on a monitor in the engineering area instilled a sense of urgency. Green meant “few changes, and the oldest change is pretty recent.” Red meant the opposite. As your repo’s bar went from green, to yellow, to red, you felt it: deploy sooner rather than later. By shedding light on the size of pending deploys, we saw deploys happening much more frequently, nearly every day. This was crucial for us to get to the third step.
Taking the plunge
Urged on by the “commits waiting” dashboard, developers were deploying much more frequently. So it wasn’t hard to take the plunge and let Jenkins deploy. Jenkins already listened for changes in our repos, building, testing, and then deploying to staging. It was one more Jenkins job to do the same thing… in production.
Here is Jenkins, sending a Slack message about an application it just deployed:

Adding automation pointed out pain points in our build. For example, one application took over 24 minutes to test and build. This made deploying painfully slow. We found a solution by moving Jenkins from a standalone machine to a cluster with multiple slaves. By breaking the application’s tests into suites, and parallelizing them with the Multijob plugin, we cut the build job from 24 minutes to 8.
With Jenkins deploying for us, we’ve become more conscious of the fact that every change needs to be production-ready. But because outgoing code changes are smaller, root-cause analysis (and rolling forward) have become much easier.

There are still areas where we need to improve (e.g. better integration testing, better feature flips) but we took a big step forward with continuous deployment. Engineers are focused on development instead of deploys, and our customers get new features faster. A big win.
